[문제]
department-highest-salary 문제 바로 가기
Department Highest Salary - LeetCode
Level up your coding skills and quickly land a job. This is the best place to expand your knowledge and get prepared for your next interview.
leetcode.com
[풀이]
SELECT de.name Department
, em.name Employee
, em.salary Salary
FROM employee em
JOIN (
SELECT departmentID, MAX(salary) max
FROM employee
GROUP BY departmentID) hi ON hi.departmentID = em.departmentID
AND hi.max = em.salary
JOIN department de ON em.departmentID = de.id
- 윈도우 함수 MAX() 이용 풀이
SELECT d.name AS Department
, s.name AS Employee
, maxsalary AS Salary
FROM(
SELECT name
, salary
, departmentID
, MAX(salary) OVER (PARTITION BY departmentID) AS maxsalary
FROM employee) s
INNER JOIN department d ON d.id = s.departmentID
WHERE s.salary = s.maxsalary;'SQL > MySQL 문제풀이' 카테고리의 다른 글
| [LeetCode] department top three salaries 윈도우함수 풀이 (0) | 2022.06.21 |
|---|---|
| [LeetCode] Consecutive Numbers 풀이 (0) | 2022.06.20 |
| [SQL DELETE문제][LeetCode] Delete Duplicate Emails (0) | 2022.06.13 |
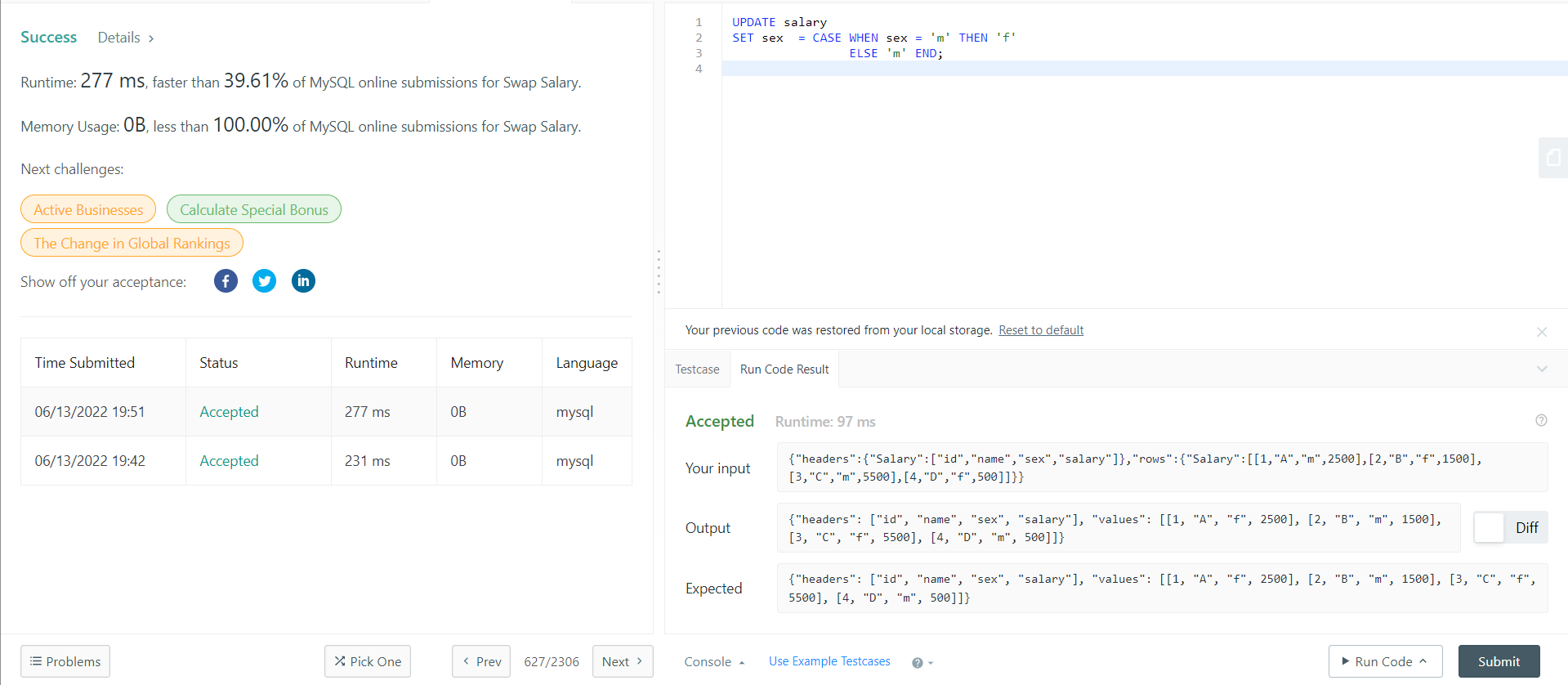
| [SQL DML문제][LeetCode] Swap Salary (0) | 2022.06.13 |
| [HackerRank] The PADS ㅡ MySQL에서 푸는 방법 (0) | 2022.06.11 |